

A keresőoptimalizálás egy méltatlanul ritkán alkalmazott technikáját vesszük ezúttal górcső alá. Bár elsőre ijesztőnek tűnhet a téma, valójában meglepően egyszerűen kezelhetők és feldolgozhatók a webszerver által létrehozott naplóállományok. Számos olyan eset van, ahol egy adott probléma hatékony felderítéséhez bele kell néznünk a szerver logokba. A cikk során áttekintjük ezen állományok értelmezését, használatát és különféle feldolgozási módjait, majd valódi példákon keresztül alkalmazzuk az ismereteket.

Jogosan merül fel a kérdés, hogy mi értelme 2017-ben nyers szerver logokat feldolgozni, amikor a legkorszerűbb nyomkövetési technológiák érhetők el bárki számára akár teljesen ingyen. A webszerver naplója mindig a legpontosabb adatokat fogja szolgáltatni az oldalon járó látogatók és különféle botok tevékenységeiről. Minden egyéb mérési és nyomkövetési módszer pontatlanabb és szűrt. Általában a robotok tevékenysége teljesen láthatatlan a statisztikákban, valamint a JavaScript-et nem engedélyező látogatók szinte teljesen követhetetlenek és mérhetetlenek a számunkra.
Vannak olyan problémák, amiknek a leghatékonyabb és legegyszerűbb megoldási módja a szerver logok elemzése. Számos esetben a probléma abból adódik, hogy a Google robotjai nem az elvárt módon járják be az oldalt. Emiatt figyelmen kívül hagy fontos részeket, túl sokat figyel lényegtelennek ítélt tartalmakat, vagy nem indexel megfelelően mindent úgy, ahogy szeretnénk.
Ahhoz, hogy a Google kedveljen egy oldalt, érdemes kényelmesen bejárható tereppé alakítani a robotok számára. A webszerver log az egyetlen olyan adatforrás, ami 100%-os pontossággal mutatja meg, hogy a botok hogyan járják be az oldalt (vagy hogyan próbálják). Egy oldal keresőoptimalizálásának nagyon jó alapozója, ha hagyjuk a Google-nek, hogy egyszerűen és gyorsan fel tudja térképezni az oldalt.
Mit akarnak a botok?
Az internetes botok skálája rendkívül széles. Egydimenziós modellt alkalmazva egyszerűen jó és rossz kategóriába sorolhatjuk őket. A jókat szeretjük, hiszen valami olyan okkal figyelik az oldalunkat (és generálnak ezzel forgalmat), amiről tudunk, és előnyünk származik belőle. A jó oldalon állnak többek között a keresőrobotok, míg a sötét oldalon találhatunk a spammerektől a scraper eszközökig számos kártékony automatát.

Tartja még magát a tévhit, hogy ezek az internetes botok csak jelentéktelen forgalmat generálnak az oldalon, így a webszerver terhelését csak minimálisan befolyásolja. Ez néhány éve valóban így volt, de az Incapsula 2016-os jelentése szerint az internetes forgalom többségét már botok generálják. Más szóval a robotok már többet neteznek, mint az emberek. Ez az arány minden bizonnyal megállás nélkül fog növekedni a következő években is a robotok javára.
Kedvenc látogatónk a Googlebot
A Googlebot olyan automata, amit a Google használ az internetes tartalmak feltérképezésére. Kedveljük, hiszen ő a keresőóriás felfedezője és hírvivője. Tartja a kapcsolatot a kereső és az indexelt oldalak között új, módosított, átirányított vagy törölt tartalmak feltérképezése által. Határozottan érdemes megfelelő körülményeket teremteni az oldalon és a szerveren ahhoz, hogy jól végezhesse a dolgát.

Mivel a Googlebot erőforrásai nem korlátlanok, így nem fog a végtelenségig próbálkozni, ha akadályokat gördítünk az útjába. Ilyenek lehetnek például különféle botcsapdák, amik végtelen ciklusba kergetik a vendégünket, vagy a túl magas válaszidők és HTTP hibakódok. Segíthetjük még a Google feltérképező automatájának a munkáját azzal, ha az oldal forráskódja megfelel a ma elvárható minimális minőségi követelményeknek. A jó és hatékony kódot a botok gyorsabban tudják feldolgozni. Bár közvetlen bizonyíték nincs arra, hogy pozitív megkülönböztetésben részesülnek a könnyebben feldolgozható kóddal rendelkező oldalak, mindenki csak nyerhet, ha ügyelünk erre.
Előfordul, hogy Googlebot-nak adják ki magukat olyan automaták, akik valójában nem azok, csak szeretnének néhány egyszerűbb szűrésen átcsúszni. A Googlebot számos IP címet használ, amik folyamatosan változnak, így nem érdemes fix IP listákkal dolgozni. Ha szeretnénk meghatározni egy IP címről, hogy valóban a Googlebot által használt címek között van-e, egy egyszerű reverse DNS kereséssel utánajárhatunk.
Hogyan működnek a szervernaplók?
Számos szoftver naplózza a futása során bekövetkezett eseményeket, hogy pontosan nyomon követhessük, hogy mi történt. A webszerverek szinte kivétel nélkül úgy vannak konfigurálva, hogy valamilyen formában naplózzák a teljes forgalmat.
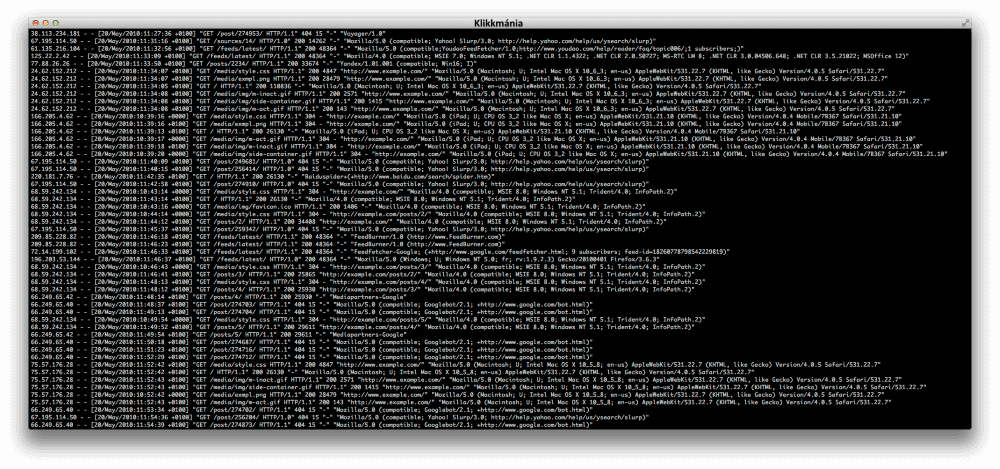
Szerencsére a legtöbb webszerver ugyanazt a szabványt használja a naplózáshoz a 90-es évektől fogva, kisebb-nagyobb kivételekkel vagy módosításokkal. Ennek köszönhetően hasonlóan tudunk feldolgozni egy Apache log fájlt, mint egy Nginx által generált naplóállományt. A szabvány szerint rögzítünk minden hit-et, ami általában egy fájl kérését jelenti a webszervertől. Ennek megfelelően egy oldal letöltése nem egyetlen hit lesz, hiszen az oldalhoz letöltünk képeket, külső JavaScript és CSS állományokat, vagy bármi mást, ami megjelenik még az oldalon. Ezek mind külön hit-ként jelennek meg. A naplók ezeket tartalmazzák.
Tekintsük át a Common Log Format szabvány értelmezését. A webszerverek legtöbb esetben ezt, vagy ennek egy kibővített változatát használják, amik valamivel részletesebb információval szolgálnak (pl. Apache Log Format vagy Microsoft IIS Extended Log File Format).
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] “GET /apache_pb.gif HTTP/1.0” 200 2326
- 127.0.0.1 – A kliens IP címe, aki a kérést küldte a webszerver felé.
- user-identifier – Egy adott TCP kapcsolatban a felhasználó azonosítására használható.
- frank – A kérést intéző felhasználó azonosítása. Általában bejelentkezett (vagy valami más módon azonosított) felhasználók egyedi azonosítóját használják itt.
- [10/Oct/2000:13:55:36 -0700] – A kérés dátuma és időpontja időzónával együtt.
- “GET /apache_pb.gif HTTP/1.0” – A HTTP üzenet, amit a kliens küldött a szervernek.
- 200 – A kliensnek válaszként továbbított HTTP állapotkód. Ebben a példában 200, tehát sikeres volt az elérés.
- 2326 – A szerver által küldött objektum mérete byte-okban.
A kiterjesztett szabványok tartalmazzák ezeket az alapvető mezőket, viszont további mezők segítésével több információt tárolnak. Ezek közül talán az user-agent a legfontosabb, ami nincs az eredeti Common Log Format szabványban. Ez megmutatja a kliens operációs rendszerét, nyelvét, böngészőjét, valamint annak verziószámát. Fontos megjegyezni, hogy úgy, ahogy egy bot kiadhatja magát Googlebot-nak, ugyanúgy kiadhatja magát bármilyen user-agent-el rendelkező látogatónak is.
Hol vannak a naplók?
Bár a naplózás helye és szabályai a legtöbb webszerver esetén részletesen konfigurálható, a legtöbb esetben az alapértelmezett beállítások vannak használatban. Nézzük meg, hogy hova naplóznak a legnépszerűbb webszerver szoftverek az alapbeállítások szerint!

Apache
Különféle Apache verziókban máshol található meg az alapértelmezett naplózási hely.
RHEL / Red Hat / CentOS / Fedora Linux Apache naplófájl:
/var/log/httpd/access_log
Debian / Ubuntu Linux Apache naplófájl:
/var/log/apache2/access.log
FreeBSD Apache naplófájl:
/var/log/httpd-access.log
Abban az esetben, ha nem találjuk, kiolvashatjuk az elérési útvonalat a konfigurációs fájlból a következő parancs segítségével:
grep CustomLog /etc/apache2/apache2.conf
Nginx
A második legnépszerűbb webszerver esetén az alapértelmezett elérési útvonala a log fájloknak itt érhető el:
var/log/nginx/
Itt az error.log és access.log szolgál hasznos információkkal.
Microsoft IIS
Indítsuk el az Internet Information Services (IIS) Manager alkalmazást. A megfelelő oldalt kiválasztva a Logging résznél a Directory field mező értékeként találjuk meg a naplófájl elérési útvonalát.
A szerver log feldolgozása
A feldolgozás során a rengeteg nyersanyagból számunkra értékes információkhoz jutunk. A szerver log elemzését számos célra használják. Nézzünk meg néhány példát:
- Fejlesztés és minőségellenőrzés
- Hálózati hibakezelés
- Támadások felderítése
- Vevőszolgálatnak részletesebb információk egy problémáról
- Technikai SEO
Természetesen ezúttal az utóbbival foglalkozunk részletesebben. A naplók elemzése általában nem egy rendszeresen végzett feladat. Akkor kerül rá sor, amikor valami probléma merül fel, és ilyen módon szeretnénk megoldást találni rá. A sorból leginkább a technikai SEO felhasználási területe lóg ki, hiszen érdemes alkalmanként egy egyszerű ellenőrzést végezni, hogy minden rendben megy-e a háttérben.
A feldolgozásnak többféle módja van. A kézi feldolgozás szinte teljesen mellőzött, hiszen nagyobb oldalak esetén percenként több ezer új bejegyzés keletkezik, amit lehetetlen átnézni. Kis oldalak esetén sem javasolt ez a mód, hiszen még ott is elveszünk a részletekben, nem látunk statisztikákat, trendeket és mintázatokat.
1. Táblázatkezelő

Viszonylag gyakori, de még mindig nem elég hatékony mód az Excel-ben vagy más táblázatkezelőben történő feldolgozás. Ehhez csupán varázslóval be kell illeszteni egy log fájl tartalmát, majd meghatározni, hogy a szóköz az elválasztójel az oszlopok között. Hátránya ennek a módnak, hogy mindig csak egy pillanatképet látunk, így nehezen veszünk észre trendszerű változásokat és átalakulásokat. Óriási naplófájlokkal meggyűlhet a legtöbb táblázatkezelőnek a baja, így csak kevés adattal tudunk ezen a módon jól dolgozni.
2. Nagyvállalati alkalmazások
![]()
A Splunk és a Sumo Logic két profi megoldás nagy adathalmazok valós idejű feldolgozásához. Főként nagyvállalatok használják a professzionális felhasználási lehetőségek és természetesen az árképzésük miatt. A Splunk-nak van egy nagyon korlátozott ingyenes változata, míg a Sumo Logic 30 napig ingyen kipróbálható teljes funkcionalitással.
3. Elastic Stack
![]()
Külön kategóriát érdemel a teljesen ingyenes és nyílt forráskódú szoftvercsomag, az Elastic Stack. Természetesen ha szerveren szeretnénk futtatni (pl. Amazon Web Services), a használat függvényében kell fizetni a szolgáltatónak, tehát csak maga a szoftver van ingyen. A programcsomag teljes megoldást nyújt a nyers naplóadatok megjelenítéséhez, feldolgozásához, elemzéséhez és archiválásához. A legtöbb esetben ez a programcsomag a megfelelő választás technikai SEO-hoz.
Technikai SEO gyakorlati példák
A nélkülözhetetlen elméleti áttekintés után itt az ideje, hogy átvegyünk néhány gyakorlati példát, amire a naplókat használhatjuk. Az itt felsorolt lehetőségek csak néhány gyakori esetet mutatnak be, amik később alkalmazhatók egyedi problémáknál is, de legalább kiindulópontként szolgálnak.
Keresőrobotok felderítése
Bár eddig csak a Googlebot-ról volt szó, minden keresőnek megvannak a saját robotjai, akik pásztázzák az internetet (hiszen erre épül a szolgáltatásuk). Természetesen mindegyik egyedi (és folyamatosan fejlődő) algoritmus alapján dolgozik, ennek ellenére elég hasonlóan működnek, és a többség tudja értelmezni a robotoknak szánt információkat (pl. robots.txt, noindex, stb.). Ha a célközönségünk által használt keresők nem tudják megfelelően feltérképezni az oldalt, értékes látogatókat veszthetünk. Ezért első körben érdemes megvizsgálni, hogy melyik keresőrobot mennyit jár a vizsgált oldalra, valamint ott mit és hogyan jár be. Bár Magyarországon toronymagasan a Google vezet a keresések számában, számos ország van, ahol ez nem igaz (pl. Oroszország, Csehország, Kína). Ha ilyen országokat is szeretnénk célozni, akkor érdemes figyelemmel tartani a többi robotot. Amennyiben valamelyik nem tudja vagy akarja bejárni az oldalt megfelelően, érdemes mihamarabb utánajárni a probléma forrásának (általában további naplóelemzéssel).
Ismét lényeges hangsúlyozom, hogy nem minden bot az, akinek kiadja magát. Az user-agent mezőben mindig csak azt tárolják a webszerverek, amit a kliensek magukról állítanak. Gyanús vagy szokatlan tevékenység esetén érdemes utánanézni a hozzájuk kapcsolódó IP címeknek.
Hibakódok

Ahogy korábban láttuk, szinte minden webszerver naplózza a kérésre adott válasz kódját. A hibakódok vizsgálata esetén az öttel és néggyel kezdődőkre kell ügyelni. Feltérképezhetjük az elérhetetlen vagy részlegesen elérhető tartalmakat, szerverhibákat vagy bármilyen más elképzelhető problémát, ami HTTP hibakódot adott válasznak.
Átirányítások

Ha egy tartalom elérési útvonala megváltozik, átirányítunk. Nem mindegy azonban, hogy milyen átirányítást használunk. Nemcsak statikus átirányítási párokat lehet meghatározni, hanem reguláris kifejezésre illeszkedő szabályok is definiálhatók. Ha véletlenül olyan címekre is illeszkedik egy ilyen kifejezés, amire nem kéne, a felhasználót átirányítjuk egy számukra irreleváns oldalra, és nem értesülünk a hibáról, hiszen csak egy szabványos átirányítás történt hibakód nélkül. Sokan használják (SEO szempontból és logikailag is) a 301-es (végleges) és 302-es (ideiglenes) átirányításokat helytelenül, így ezeket mindenképpen érdemes szemügyre venni. Ilyen és ehhez hasonló eseteket deríthetünk fel az átirányítások vizsgálatakor.
Crawl budget pazarlás
Először tisztázzuk a crawl budget jelentését. Ehhez két további fogalommal kell megismerkedni. Az egyik a crawl rate limit, ami azt a célt szolgálja, hogy a Googlebot csak annyira terhelje le a webszervert, hogy az ne legyen túl sok. Egyszerűsítve az határozza meg, hogy mekkora bot terhelést bír ki a szerver jelentős lassulás nélkül. A másik jelenség crawl demand, ami azt jelenti, hogy mennyire érdeklődik a Google az adott oldal feltérképezése iránt. Népszerű és értékesnek ítélt oldalak esetén ez természetesen magas, de érthető módon a rossz minőségű tartalomra nem tart olyan nagy igényt a Googlebot, inkább más vizekre evez.

A crawl budget az imént ismertetett két jelenség elegye. A Google magyarázatában a crawl budget azoknak az URL-eknek a száma, amit a Googlebot tud és szeretne is bejárni egy adott időn belül.
Bár Gary Illyes szerint a legtöbb oldalnak egyáltalán nem kell aggódnia a crawl budget miatt, előfordulnak esetek, amikor helytelen beállítások miatt értéktelen vagy lényegtelen tartalmak bejárására “pazaroljuk” ezt a keretet más, fontosabb oldalak rovására. Így előfordulhat, hogy a kevésbé fontos részekre elmegy a napi limit, és még azelőtt elhagyja az oldalt a Googlebot, hogy a lényegre térhetne.
Fontos, hogy helyesen használjuk a robots.txt-t és a meta robot tageket, hogy minimálisra csökkentsük a napi veszteséget. Ha mindezek ellenére túl sok a napi pazarlás, érdemes alaposabban utánajárni a jelenség okának.
Többszörös bejárás
Gyakori probléma, hogy ugyanazt az oldalt a keresőrobotok többször is bejárnak, mert különböző url-ekről is elérhető. Egy hétköznapi példa, amikor különféle URL paramétereket használunk mérésre vagy akármilyen marketingcélra. Ekkor ugyanaz a tartalom elérhető szinte végtelen elérési útvonalon (a paramétereket variálva).

Szerencsére a Google Search Console-ban beállítható részletesen, hogy a Google hogyan értelmezzen bizonyos URL paramétereket. Ez a probléma szorosan kapcsolódik az előző ponthoz, hiszen itt is crawl budget-et pazarlunk, kockáztatva, hogy más fontos oldalakra nem jut már keret.
Bejárási prioritás
Előfordul, hogy a Google bizonyos oldalakat (vagy teljes részlegeket) nem látogat elég rendszeresen, tehát nem kezeli a megfelelő prioritáson őket. Ha azt tapasztaljuk, hogy valami túl nagy vagy túl kevés figyelmet kap a keresőóriástól, ajánlatos lépéseket tenni a fókusz módosítása érdekében. Először érdemes átnézni és (ha szükséges) újratervezni a belső linkelési stratégiát, hiszen jó eséllyel azért nem tart valamit fontosnak a Google, mert mi is azt mutatjuk róla a linkstruktúra alapján. Ha még ez sem elég, az XML Sitemap-ben be lehet állítani bejárási prioritást. Így kikényszeríthetjük, hogy ne foglalkozzon annyit a túl sokat bejárt részekkel, a fontos, de hanyagolt oldalak javára.

A keresőoptimalizálást igazán nehéz jól csinálni, hiszen számos, hozzá kapcsolódó területet nemcsak értenünk kell, hanem adott esetben használni és az előnyünkre fordítani. Ilyen a webszerver naplóállományainak az értelmezése és feldolgozása. Ahogy láthattuk a példákban, vannak olyan problémák, amiknél nem lehet (vagy legalábbis nem érdemes) elkerülni a szerver logok bevonását a megoldásba. Érdemes megbarátkozni ezzel a területtel, mert jóval egyszerűbb annál, mint amilyennek tűnik, és cserébe nagyon jól használható gyakorlati tudással gazdagodhatunk.



